国产工业软件特惠推广月,有意者关注公众号PLM Vision发送“二维码“添加管理员!
一、为什么要做“文档语义化”?
在 PLM中,我们存了大量:
设计说明书(Design Spec)
工艺文档 / 作业指导书
变更说明(ECR / ECO)
问题分析报告(8D / RCA)
IT 运维文档 / 配置说明
但这些文档在系统中的真实状态是:
系统只“认识文件”,不理解内容
检索只能靠标题、属性、关键字
新人找不到,老人懒得找
问题反复出现,却无法复用历史经验
👉 这不是 PLM的问题,而是传统 PLM 对“文档内容”的理解能力有限。
AI 能解决什么?
AI 并不是简单做全文搜索,而是:
理解文档“在讲什么”
理解不同文档之间的“语义关系”
用自然语言回答工程问题
而这一切的第一步,就是:
文档语义化(Document Semanticization)
二、什么是“文档语义化”?
一句话定义:
把“人能读懂的文档”,转化为“AI 能理解、可计算的语义向量”。
从三个层次理解
一个直观例子
你问系统:
“ECO 生效后,BOM 不一致一般怎么处理?”
传统方式:
你要自己想关键词
打开一堆文档逐个看
语义化之后:
历史 ECO 说明
BOM 调整规范
相关问题处理案例
AI 自动定位到:
直接给你总结答案
⚠️ 注意:
这一步还不是大模型推理,而是“让文档可被 AI 理解”。
三、整体技术架构(先看全景)
用一句话概括本篇的方案:
PLM负责“权威数据源”,AI 知识库负责“语义理解与问答”。
架构链路

你会发现:
Teamcenter 不需要改核心代码,老版本的Teamcenter也可以支持
AI 系统不直接“侵入”PLM
两边解耦,但通过“文档”形成数据主线
四、怎么做(Step by Step,以Teamcenter为例)
下面进入真正“能落地”的部分。
Step 1:通过 Teamcenter Handler 导出文档
为什么用 Handler?
原因很现实:
文档导出需要权限控制
要与流程(Workflow)绑定
需要自动化、无人值守
典型触发场景:
文档发布(Release)
流程完成(EPM 完成节点)
状态从 Working → Released
技术方式
使用 EPM-invoke-system-action
调用 bat / shell / perl 脚本
通过 ITK:
下载 Dataset 文件
按规则重命名
输出到指定目录
导出目录示例:
C:/EasyKB/
├─ Files/
👉 到这一步为止,Teamcenter 的职责已经完成。
Step 2:EasyKB 启用“监控文件夹模式”
这是整个方案里最关键、也是最优雅的一步。
为什么不用 API 对接?
很多人第一反应是:
“是不是要 Teamcenter 直接调 AI API?”
但在企业里,更推荐:
文件即接口(File as Interface)
解耦、稳定、可审计
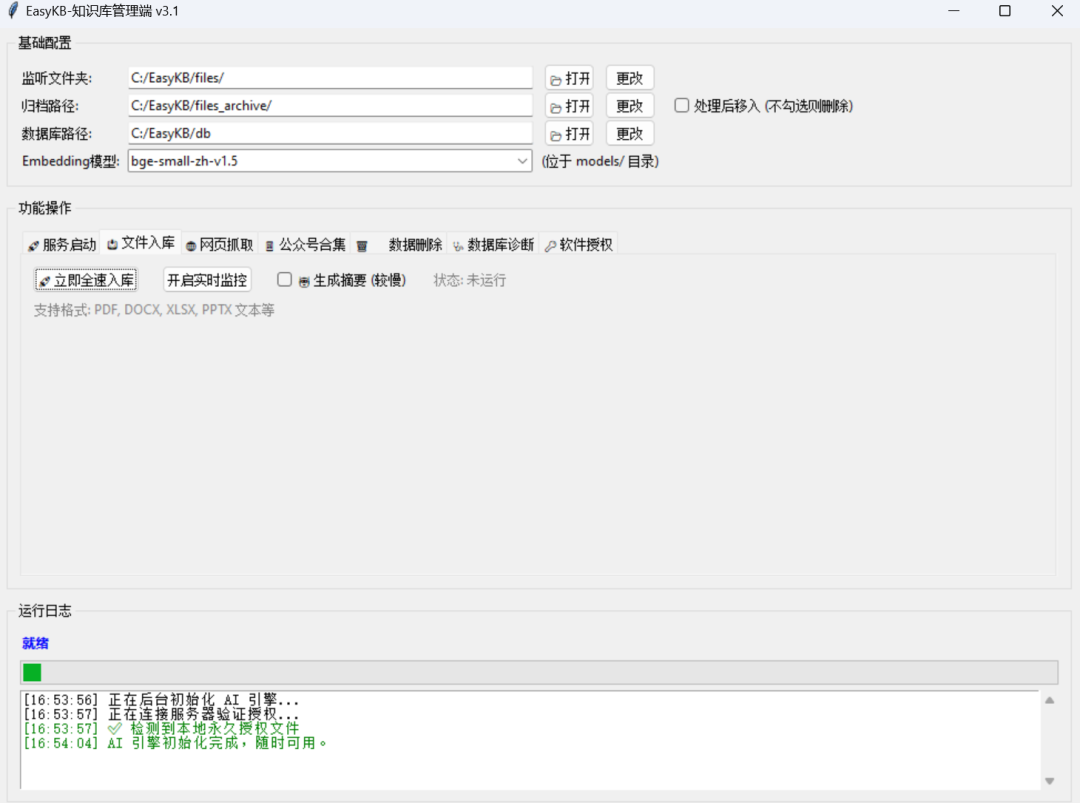
EasyKB 的监控模式做了什么?
实时/定时扫描指定目录
自动识别文件类型:
PDF / DOCX / TXT / MD
文档拆分(Chunking)
自动生成向量(Embedding)
写入向量库 + 元数据索引
你不需要:
写一行 AI 代码
理解向量数学
自己维护索引
元数据示例
{
“source”: “Teamcenter”,
“doc_type”: “ECO”,
“object_id”: “ECO000123”,
“revision”: “A”,
“release_date”: “2025-01-10”
}
这些信息,后续会极大提升检索精度。
Step 3:自动向量化并入库
这一阶段完全由 EasyKB 完成:
文档内容 → 向量
向量 + 元数据 → 知识条目
支持:
相似度检索
Top-K 召回
跨文档语义匹配
你可以把它理解为:
为工程文档建立了一套“AI 可计算的大脑索引”。
Step 4:通过浏览器访问 AI 知识库
最终用户侧,体验非常简单。
使用方式
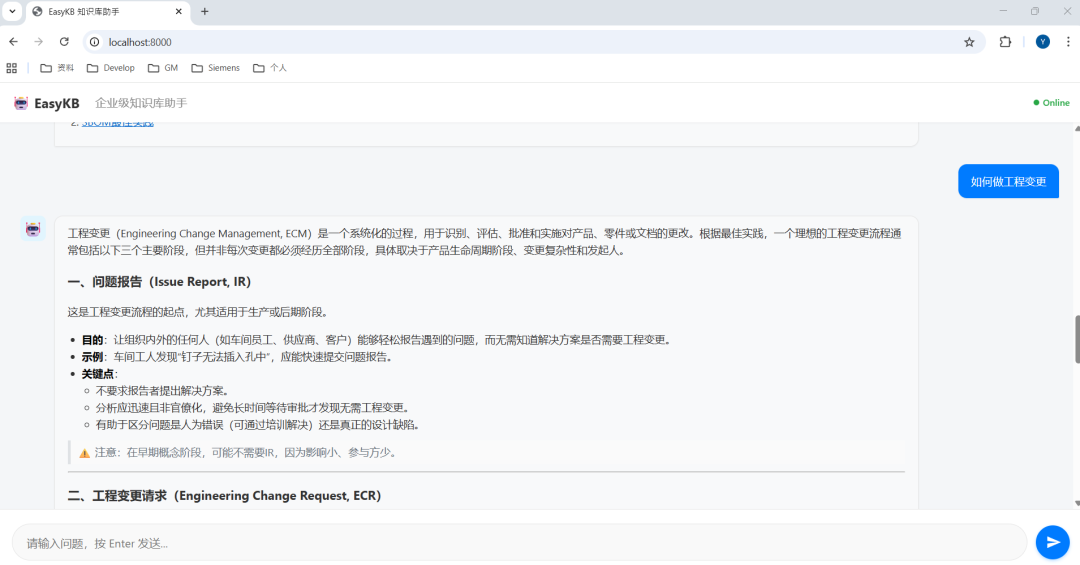
浏览器打开 EasyKB Web
用自然语言提问,例如:
“ECO 生效后 BOM 不一致怎么办?”
“有哪些流程节点会触发文档导出?”
“历史上类似的工艺变更怎么处理的?”
背后发生了什么?
语义检索相关文档片段
LLM 基于检索内容生成答案
可回溯原始 Teamcenter 文档
👉 这一步,工程知识终于“活”了。
六、本篇你应该带走的 3 个关键认知
1️⃣ 文档语义化不是“智能搜索”,而是 AI 能力的地基
2️⃣ Teamcenter 不需要 AI 化,只需要“数据可被 AI 使用”
3️⃣ 文件夹监控模式,是企业级落地 AI 的最优解
咨询合作请关注公众号回复“二维码”添加管理员微信。
七、下一篇预告
《PLM AI 实战指南(2)》将重点解决一个更难的问题:
术语归一化 —— 为什么 AI 总是“听不懂”工程语言?
同一个东西:
零件 / 物料 / Part / Item
同一个动作:
发布 / 生效 / 冻结 / Release
👉 不解决术语问题,AI 永远只能“像新人”。
如果你正在做:
Teamcenter 二次开发
PLM + AI 落地
企业知识库 / 智能问答
这套方法,不是概念,而是已经能跑起来的工程方案。